Why Neural Networks Aren’t Actually Intelligent

As artificial intelligence systems become more capable, the boundary between machine processing and human cognition begins to blur. The neural networks behind many of today’s large language models can almost flawlessly imitate language, creativity, and problem-solving. However, there remains an important distinction to be made: do these systems truly understand and demonstrate genuine intelligence, or are they simply predicting patterns and returning outputs that appear correct?
Artificial Intelligence: The big picture
Today, many of us, if not all of us, have come across and interacted with AI in some form or another. Whether that be through the AI overviews in our browsers, image generation or perhaps even as a helping hand for schoolwork. Now more than ever, AI is seeping into more and more aspects of our daily lives. Artificial intelligence is an umbrella term, encompassing many different areas. The earliest forms of AI - as we know it today - were rule-based, symbolic systems. They were built on logical rules that dictated the behaviour of the system, using an extensive knowledge base built on the existing knowledge of experts in their fields.
The famous chess engine Stockfish was built on this basis of using a predefined set of rules to play the most optimal game. The engine originally worked by generating a search tree, accounting for every possible move and the resulting position. By finding the best path through the tree, it found the sequence of moves that maximised the player's chances of winning. Rule-based systems represent a foundational approach in AI, characterised by their reliance on an explicit rule set. With the advancement of processing power, most of today's models are built on machine learning.
These models draw patterns from data instead of being explicitly programmed with rules. Huge amounts of data, numbers, photos or text are collated to be used as training data, which is fed into the model. Developers can choose a machine learning model to use, supply the data, and let the model train itself to find patterns or make predictions, allowing it to make inferences after being trained on on this information. Neural networks are an example of one of the most widespread models used for machine learning.
What is a Neural Network?
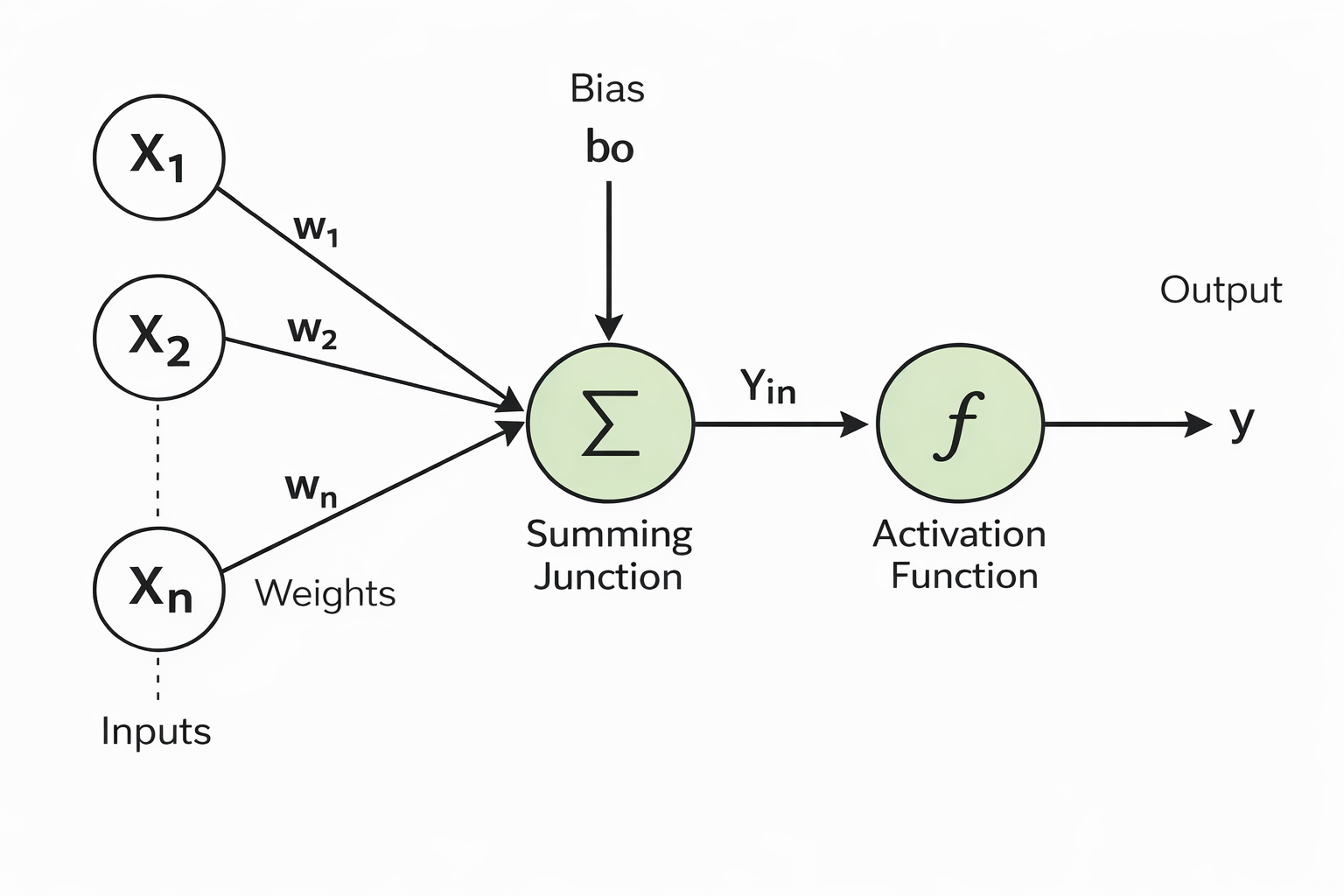
A neural network is a computational system inspired loosely by the brain. It is made up of layers of interconnected nodes, each of which is an artificial neuron. These transform inputs into outputs. Each connection carries a certain relevance, which determines how strongly one neuron influences another. When inputs pass through the network, they are combined, deciding what information is passed to the next layer, and ultimately produce an output by making decisions using the network that is formed.
An example of a neural network in action could be through an email spam detection system. An email is fed into the network, with words or phrases commonly associated with malicious emails such as “urgent”, “money” or “win” taken as inputs. The earlier layers of the network decide the importance of this information, while later layers combine this earlier information to decipher more advanced nuance like context and tone. The final layer then could uses all the previous information to output a probability of whether the email is likely spam; if that probability is high enough, the email is flagged. Neural networks take unimportant individual aspects and combine them, drawing conclusions to create meaningful inferences.
The processes that a neural network undergoes can be abstracted down to the following two stages:
Step 1: Combining the Inputs
The neuron first calculates a weighted sum of all its inputs using the following formula:
$$z=\sum_{i=1}^{n} w_i x_i + b$$
· $x_i$ represents the inputted data. These are the pieces of information the neuron receives. For example, in an image recognition task, each input might be the brightness of a pixel. In a language model, it could be how often a word appears in a sentence.
· $w_i$ represents the weights. Weights are values given to the connections between nodes. They dictate how much influence each input has on the network’s final output. The greater the weighting, the greater the influence a given connection will have on the output.
· $b$ represents the bias. A bias is added to the weighted sum. Bias shifts the output of the operation to allowing the network to still work with data even if all input values are zero. It adjusts values so that it can still provide relevant information regardless of the input.
· Together, they form the weighted sum, $z$ , a combination of multiple inputs, where each input has a different level of importance (its weight). It’s a single value that summarises all the inputs, considering which ones matter more.
Step 2: Deciding What to Output
After calculating the weighted sum, the neuron passes it through an activation function.
$$a = \sigma(z)$$
$sigma$ is the activation function that is applied to the weighted sum. The activation function decides how the neuron should activate and if it will pass information to the next layer or stay inactive. It determines the inputs “relevancy” to the output. Common activation functions include:
- Step functions that return a simple yes/no decision.
- Sigmoid that offer a smooth output between 0 and 1, often interpreted as a probability. This is the most common.
- ReLU (Rectified Linear Unit) that outputs 0 for negative inputs and keeps positive values, helping the network learn efficiently.
During this process, the network is exposed to large amounts of data along with the expected outcomes. The network makes predictions based on the current set of weights and biases, then compares these predictions to the correct answers. Any discrepancies, known as errors, are used to adjust the network’s weights and biases through a process called backpropagation. It works by calculating the gradient of the error with respect to each weight in the network, essentially figuring out how changing each weight will contribute to the error and working to minimise this. The network then updates the weights in the opposite direction of the gradient to reduce the error. By repeating this process many times over all the training data, the network gradually improves its accuracy and effectively “learns” from its mistakes. This allows the network to fine-tune itself to more effectively and reliably recognise the patterns present in the data.
The Limits of Neural Networks
What neural networks excel at is pattern recognition, where huge amounts data exists and a task is easily repeatable. They do not understand concepts the way that humans do, but they can identify tiny correlations in vast datasets that would go completely unnoticed under the human eye. A language model may be able to generate coherent writing but only because it has learned the statistical relationships between words and phrases in the texts that it was trained on. Similarly, an image recognition network can detect objects in photos not because it “knows” what a cat is, but because it has learned the patterns of pixels that commonly occur in images labelled as cats.
Despite their impressive performance, neural networks have clear limitations. They fail outside of the data they were trained on, often “hallucinating” to produce a seemingly coherent response. They cannot reason abstractly, understand context in the way humans do, or apply existing knowledge effectively to new domains in the way humans can. Each output is ultimately the result of billions or even trillions of mathematical calculations drawing patterns in the data, not a conscious understanding of meaning. They are limited by their very framework, human nuance and reasoning are impossible to capture in mathematical methods. While humans can draw on sensory experiences, intuition, and abstract reasoning, neural networks are limited to the correlations present in the data they have already seen.
Neural Networks as Building Blocks for Future AI
While neural networks may not be intelligent in the human sense, they are still incredibly powerful tools. Their ability to process and learn from enormous datasets still holds scope for huge utility, from image and speech recognition to autonomous vehicles and the large language models many of us already interact with daily, AI is clearly here to stay. Emerging approaches, such as neurosymbolic AI, aim to combine the powerful pattern recognition of neural networks with the reasoning of logic-based methods. By doing so, future AI systems may overcome some of the current limitations, becoming better at reasoning, abstraction, and reliability whilst also leveraging the immense computational power of neural networks.
In this sense, neural networks are less a form of intelligence and shouldn’t be thought of in that way, but more an incredibly model and a hugely powerful tool, capable of performing tasks that were once seen as uniquely “human”. Understanding their capabilities and limitations helps us appreciate both the revolutionary potential of neural networks and the important distinction between simulated intelligence and true, human-like understanding.
Bibliography:
Rule-based system in AI - GeeksforGeeks
Maximizing stockfish's potential: A speed experiment on cloud servers - Chessify
Game theory: How stockfish mastered chess - Cornell University
Machine learning, explained - MIT Sloan
What is machine learning (ML)? - IBM
Neural networks - What are they and why do they matter? - SAS
Explained: Neural networks - Massachusetts Institute of Technology
What is a neural network? - IBM
Weights and bias in neural networks - GeeksforGeeks
Backpropagation in neural networks - GeeksforGeeks
What are neural networks not good at? On artificial creativity - Anton Oleinik
Why Gen AI will never achieve human level intelligence - Virtual Blue



