Gaming with AI

Legacy articles aren't reviewed and may be incorrectly formatted.
Gaming with AI
Games have long played an important role in human culture, being one of the earliest forms of entertainment and social interaction. From the earliest forms of Mancala discovered in Africa 6000 years ago, to the board games in Europe that became the modern game of chess, games have been developing in complexity and nuance while still entertaining people. Now, with the power of computers, more detailed, complex and possibly more enjoyable digital games have been created, driving social entertainment into the digital age.
With the power of computers, developers were able to create games that do not require people to play against each other, but play against computers instead. At first, games were created which replaced the other player(s) with computers, like in 1952 when British professor A.S. Douglas created the game noughts and crosses on a computer in University of Cambridge. This may be the first form of AI appearing in gaming as an opponent, despite the fact that the “AI” in that game was just a simple algorithm following certain steps depending on the input data. That, of course, was not the modern-day concept of machine learning – computers at the time were too slow and not powerful enough to do that. For example, the famous Space Invaders performed functions on the player’s input, layered with random movement that creates a greater difficulty for players. Pac-Man, a name that probably you have heard of, was one of the first to introduce a “personality trait” into each enemy AI, adding a difference to every single enemy, at the same time making their movement even harder to predict.

[The all-time classic arcade game: Pac-Man]
Alongside with the enemy AI in computer games, projects have also been set up to beat human in those more traditional board games. When Garry Kasparov was beaten by Deep Blue in 1997, which marks the overtaking of humans by computers at chess, the potential of computer processing was again displayed to the public. However, behind Deep Blue, the fundamental algorithm was not “intelligent” – it carried out a search algorithm, going through all the possible routes on a chess board to find the best move.
Compared to the possible moves of 1040 in chess, which meant that it was possible to brutally search through the moves, Go, a board game with origins in China, has an incredible number of 10360 possible moves in a game. This meant that the old method of searching for the optimal path in a data tree would simply not work anymore. Therefore, the concept of “neural network” was used. The name represents the inner workings of the algorithm, as a comparison to the neural links in human brain. Inputs are given to the algorithm, and the data would pass through multiple layers of “nodes”, which are accordingly given more weight each time if the previous move appears to be successful. In order to create AlphaGo, DeepMind started off by passing in hundreds of thousands of games of Go played by humans to let the network learn from the moves played by human players. Then it played against different versions of itself countless times, learning from the mistakes it made each time. This eventually led to a victory against world champion Ke Jie in May 2017, a feat which marked AI taking the crown in the hardest board game ever.

[Kie Jie in his second match against AlphaGo]
[AFP/Getty Images]
Then the attention started to turn to video games once again. Given the advancements made in video games, the number of possible “moves” is even more astronomical, given that most of the games are based off a 2D plane. The DeepMind team was again one of the first to step into this field. They created AlphaStar, an AI aiming to conquer the game StarCraft II. The start was difficult – there were so many processes that the AI could carry out near the start of the game that would massively affect the entire game. This had led to the team putting in some latent data that made sure the AI has a decent start, based off what the professional players do in this game. Then another problem arose. The problem did not manifest itself in games like Go or Chess as much, and that is “forgetting”. The AI started to forget how to beat the previous versions of itself, creating a cycle like “chasing its tail”. Using a simple game, rock, paper and scissors: as self-play carries out, the AI will go around thinking each one of them is the best tactic, never escaping this endless cycle.
So, how was it solved? The team found that fictitious self-play, meaning that the AI played against a mixture of all the previous strategies it had used, was part of the solution. But that was just not enough for StarCraft II. Consequently, “The League”, was introduced. The main purpose of the League was to exploit the weaknesses of the main AI, through putting in exploiter AIs. The aim of the exploiter AIs was not to win against every single opponent, but to find out the flaws in the tactics of the main AI, making it stronger in that way. Through the League, AlphaStar was able to learn all the complex strategies of StarCraft II fully automated, without the need of feeding in data from pro plays like what AlphaGo used. With these algorithms, AlphaStar achieved the Grandmaster League in the game, which meant that it was one amongst the 700 best players in the world. It is the first AI to reach the top league in a popular esport without any restrictions. However, it has still got some way to go before it beats the best pro players.
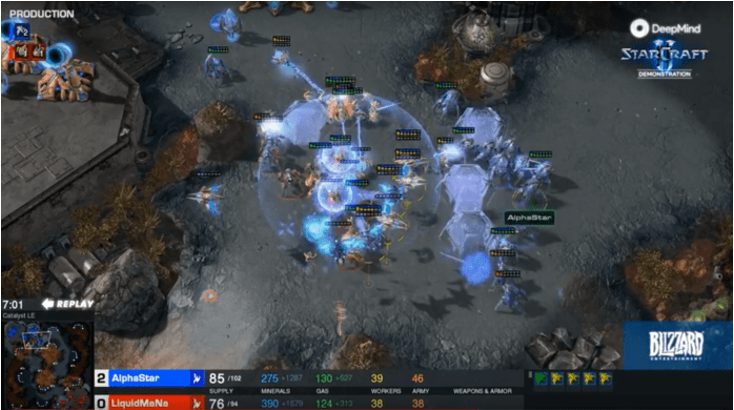
[AlphaStar winning a match against a semi-pro]
Moving onto another project – OpenAI Five, which was trying to tackle the game Dota 2. This time, alongside with all the problems that AlphaStar had, a brand new problem appears: teamwork. The OpenAI team tackled it through putting in a hyperparameter (a value fed into the network controlling its learning processes) called “team spirit”. This controls how much each of the five AIs valued their individual gain over rewards for the whole team. This value is changed throughout the project based on the results that the AI give. That is the prototype of the teamwork between different neural networks, for which I believe lots of different strategies will emerge in the future. Lots of progress had been made, as OpenAI Five has beaten some semi-pro teams, but still with restrictions of heroes that were chosen, and certain features of the games were taken out.
So, what can these AIs give to humanity? Going back to chess, the top players now use computers to analyse their games as well as their opponents’, allowing them to spot their mistakes in the game, furthering the boundaries of human chess. After AlphaGo, DeepMind created AlphaZero, where no data of games played by humans was ever put in. All it knew was the basic rules of the games of chess, shogi (Japanese chess) and Go, and through self-play, it taught itself to beat the world champions in all three games. It has an unconventional style of playing, many of its ideas being taken up by human into their own games. Garry Kasparov once said: “I can’t disguise my satisfaction that it plays with a very dynamic style, much like my own!” Projects like AlphaStar and OpenAI Five, due to the games more resembling the real-world situations where decisions need to be made quickly with countless possibilities, many new algorithms and methods of solving problems for the AI have been developed. These new ideas are not restricted under “games”. They can be applied in other real-world situations such as law or healthcare. No one quite knows the bounds!
References:
https://en.wikipedia.org/wiki/Deep_Blue_(chess_computer) Wikipedia
https://en.wikipedia.org/wiki/Artificial_intelligence_in_video_games Wikipedia
https://en.wikipedia.org/wiki/Artificial_neural_network Wikipedia
https://en.wikipedia.org/wiki/History_of_games Wikipedia
https://deepmind.com/research/case-studies/alphago-the-story-so-far DeepMind
https://deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning DeepMind, October 30, 2019
https://openai.com/blog/openai-five/ OpenAI, June 25, 2018
https://www.history.com/topics/inventions/history-of-video-games History.com editors, September 1, 2017

![Image via [Adobe Stock]](/content/images/size/w600/2026/03/IMG_0874.jpeg)
